Правовые аспекты искусственного интеллекта и смежных технологий: права на контент, созданный с помощью машинного обучения

"Журнал Суда по интеллектуальным правам", № 2 (36), июнь 2022 г., с. 21-32
Постановка проблемы
Правовые вопросы искусственного интеллекта и смежных технологий — популярная и важная тема современных научных дискуссий. В её рамках обсуждается множество теоретических и практических проблем: гражданская правосубъектность роботов и ответственность за их «деяния» [7, с. 87], обеспечение безопасности при использовании искусственного интеллекта [2, с. 773], взаимодействие работников и искусственного интеллекта [17, с. 71], защита конфиденциальной информации [4, с. 141–143], охрана интеллектуальной собственности [4, с. 143, 146–147].
Данное исследование посвящено проблеме прав на контент, созданный с помощью машинного обучения. Под «контентом» понимается текст, изображение, аудио или видео. Машинное обучение пока можно рассматривать как синоним искусственного интеллекта, а уточнения по поводу использования этого термина будут далее.
Поясним проблему на примере.
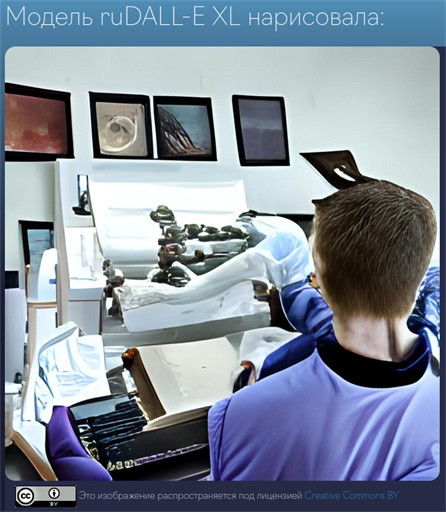
Рисунок 1. Скриншот страницы с изображением, сгенерированным с помощью модели ruDALL-E.
Выше представлено изображение, сгенерированное с помощью модели ruDALL-E XL по запросу «робот-художник»1. Модель ruDALL-E — это обученная нейросеть, которая делает картинку по текстовому описанию. Обратим внимание на любопытные детали: внизу указано, что «изображение распространяется под лицензией Creative Commons BY», а сверху написано, что его нарисовала «модель ruDALL-E XL». Иначе говоря, разработчики косвенно говорят, что изображение — объект авторского права, на него предоставлена открытая лицензия и что автор — это нейросеть2. Не опрометчивый ли это шаг, ведь вопросы о правах на «произведения», созданные искусственным интеллектом, остаются спорными?
Цель данной работы — предложить вариант решения проблемы интеллектуальных прав на результаты «творчества» искусственного интеллекта, опираясь при этом на определённые методологические предпосылки. Первая — научный редукционизм: не создавать новые сущности там, где можно обойтись без них. Применительно к праву это значит быть консервативным и не вводить новые правила, пока не доказано, что они нужны. Вторая — правовой конструктивизм: право — это искусственное образование, которое человек придумал для решения определённых задач и достижения определённых целей3. При таком подходе нет «хороших» или «плохих» вариантов, а есть разные цели и задачи, разные правила и разные эффекты этих правил. Третья — это связь права с реальностью: правила создаются людьми, но должны опираться на положение дел в реальном мире, а не быть чистой абстракцией и не исходить из массовых представлений. Так, хотя для обывателя наличные деньги и «деньги на банковской карте» — это примерно одно и то же, с точки зрения юристов безналичные денежные средства — это право требования к банку, а не разновидность наличных денег. Точно так же не следует забывать о том, как на самом деле работает искусственный интеллект, пусть даже бытовые представления отличаются от реального положения дел.
Данная работа привязана к российской правовой системе. В каком-то смысле это проявление редукционизма и в то же время стремления найти концептуальное решение. Проблема сложная, поэтому лучше сконцентрироваться на одном правопорядке, чем пытаться охватить множество разных подходов из разных стран. Нюансы и многообразие важны как источник новых идей, но для логического решения проблемы от них лучше абстрагироваться. Кроме того, в данной работе почти не будет анализа конкретных кейсов, потому что хочется избежать казуистичности. Кейсы — это отдельные события и вытекающие из них действия, в которых много случайного. Они могут быть интересны, но вряд ли стоит делать поспешные обобщения. Таким образом, данная работа — это в первую очередь теоретическое исследование, а не сравнительный анализ и не case study, и примеры разных правопорядков или конкретных ситуаций упоминаются в качестве иллюстраций, а не аргументов.
Дальнейший текст разделён на три части. В первой делаются важные терминологические уточнения и описываются неявные предпосылки, лежащие в основе многих исследований о правовых аспектах искусственного интеллекта. Задача — обратить внимание на стереотипы языка и мышления, которые могут приводить к некоторым искажениям и предвзятости при дальнейшем рассуждении. Далее идёт часть о том, умеет ли искусственный интеллект творить и можно ли считать его «продукты» объектом интеллектуальных прав. Наконец, третья часть — это рассуждение о том, кого можно назвать автором и правообладателем «произведений», созданных с помощью искусственного интеллекта. После этого подводятся краткие итоги.
Понятие искусственного интеллекта: от «Терминатора» к перемножению матриц
Традиционное начало юридического исследования — это работа с понятиями. Право опирается на логику, поэтому если качественно сконструировать понятия, то многие проблемы легко решаются по правилам формальной логики. Работы об искусственном интеллекте также часто начинаются с определений (см., например, [13, с. 94–95]).
В юридической литературе множество подходов к понятию искусственного интеллекта. Нет смысла пересказывать все определения, тем более что многие из них выглядят как длинный абзац текста и только затруднят чтение. Однако стоит обратить внимание на различия подходов. Среди определений есть простые и краткие (например, определение из энциклопедии «Британика», которое цитируют Ю.С. Харитонова и В.С. Савина [18, с. 528]), а есть сложные и длинные (часто цитируемое определение И.В. Понкина и А.И. Редькиной занимает полстраницы текста — см. [13]). Одни из них тяготеют к философии [21, с. 43–44], другие опираются на психологию и инженерию с элементами нейрофизиологии [9, с. 69], третьи существуют в рамках компьютерных наук (в частности, «классическое» определение искусственного интеллекта, данное Дж. МакКарти в 1956 г. — см. [15, с. 77]). В некоторых работах искусственный интеллект рассматривается в связи с робототехникой [10, с. 7], а в других подчёркивается, что он может существовать отдельно от роботов [7, с. 82]. Ещё один распространённый подход к анализу понятия — это взять определение из нормативно-технического документа [7, с. 83], стратегии [18], государственной программы [6, с. 25] или иностранного закона [3, с. 42–43]. В конечном итоге получается, что есть около 15 естественно-научных определений и нет легального [15, с. 78].
В ситуации, которая сложилась с понятием искусственного интеллекта, таятся опасности для исследователя. Иногда многообразие подходов полезно, но в данном случае лишь усложняет понимание и уводит от сути. Сам выбор понятия настраивает на конкретный ход мыслей, и то же самое можно сказать об определении. Иначе говоря, понятие и определение имеют методологическое значение и влияют на рассуждение. Если они запутанные и всеохватывающие, то и мысли будут запутанными и всеобъемлющими. Если определение создано в конкретной парадигме, то автор присоединяется к этой парадигме, даже если не хочет того. Следовательно, необходимо обговорить характерные особенности существующих определений и объяснить, какие сложности они могут создать для исследователя.
Первая проблема — определения охватывают крайне широкий круг явлений: от систем, предлагающих похожие видео, и голосовых помощников, читающих новости и включающих музыку, до автопилотов, боевых дронов, интеллектуальных систем продувки расплавленного чугуна и даже чипов, вживлённых в мозг. Подход к их регулированию вряд ли может быть одинаковым. Но если определения конструируются для решения задач регулирования, то они должны соответствовать этим задачам. Например, определение, сделанное для регулирования «умных» персонажей в компьютерных играх должно отличаться от определения, сделанного для регулирования беспилотного транспорта. Одно «зонтичное» понятие на все случаи жизни приведёт лишь к тому, что в праве появится конгломерат явлений, общее у которых только название: «искусственный интеллект». Но такое обобщающее понятие может повлечь лишь непонимание и логически верные, но чисто умозрительные и не имеющие отношения к действительности построения.
Вторая проблема — определения искусственного интеллекта слишком сложные. Они часто содержат упоминания о разуме и мышлении [19, с. 33–35], рефлексии, восприятии и самоидентичности [21, с. 43–44], киберфизических и био-кибернетических системах, самоорганизации, гомеостазе, антропоморфности, обучении и самообучении [9], и, конечно, о «естественном» интеллекте. Любая попытка прочитать определение и выяснить, что такое искусственный интеллект, автоматически уводит к вопросам о том, что такое интеллект естественный, что такое разум, рефлексия, мышление, обучение и заставляет погрузиться в дебри философии, психологии, инженерии. Это весьма сомнительный путь: все равно до конца непонятно, что такое интеллект и сознание и как они работают у человека. В то же время они воспринимаются как нечто, свойственное самому человеку, а любая «интеллектуальная деятельность» машины сравнивается с аналогичной деятельностью человека. В конечном итоге получается, что любое определение искусственного интеллекта — это по сути попытка описать, что такое интеллект человека, объяснить, из чего он состоит и как работает, после чего сделать вывод: если у компьютера хотя бы что-то происходит так же, то это, видимо, искусственный интеллект. Более сложные определения скорее запутывают исследователя (исключая ситуацию, когда единственная цель — сконструировать определение) и тем самым мешают ему. Кроме того, сложность определений вредна и для практики. Искусственный интеллект — это массовое явление уже сейчас. Если регулировать его, то правила должны быть понятны каждому. Любой человек, не обладающий профильными знаниями, должен взглянуть на робота или компьютер, после чего открыть закон, прочитать определение и понять, относится ли оно к этому роботу или компьютеру. Если же исследователи формулируют научные определения так, что для их понимания нужно открывать толковый словарь, то и легальные определения вряд ли получатся простыми и ясными.
Третья проблема — сам термин. Традиционно искусственный интеллект делят на «сильный» и «слабый». Сильный полностью ведёт себя как человек и решает любые задачи, а слабый слегка имитирует человека и решает некоторые задачи [11, с. 532]. Сейчас существует только слабый [4, с. 138]. Вместе с тем при анализе юридических дискуссий не покидает ощущение, что большинство авторов воспринимает искусственный интеллект как сильный или считает его появление делом ближайшего будущего. Исходя из этого они делают прогнозы, строят планы и предлагают концепции. Но cильного искусственного интеллекта пока нет. Да, о нём говорят с середины прошлого века и уже многократно обсудили «восстание машин», но неизвестно, когда он появится на самом деле и каким будет. Таким образом, рассуждения о сильном искусственном интеллекте — это по-прежнему научная фантастика. Впрочем, фантазия — это тоже важная часть научного поиска. Плохо другое: гипотезы о сильном искусственном интеллекте искажают оптику. Говоря о слабом искусственном интеллекте, исследователь в первую очередь видит слова «искусственный интеллект», и в голове поневоле возникают ассоциации с «Терминатором». Вероятно, сказываются и обыденные представления: разговаривая с голосовым помощником на телефоне или с чат-ботом, сложно избежать мысли о том, что это «существо» думает как человек. Однако интеллекта там нет — есть алгоритм, который получает короткую аудиозапись и выдаёт в ответ другую короткую аудиозапись. Этот алгоритм необязательно имитирует мышление человека: широко известные нейронные сети — лишь одна из возможных технологий. В общем виде это выглядит так: есть некий чёрный ящик, который берёт данные, как-то обрабатывает их внутри себя и выдаёт наружу другие данные. Тем самым алгоритм выполняет некоторые задачи, которые раньше предназначались только для человека, но не становится от этого сущностным подобием человека. Точно так же печатный станок, изобретение XV в., выполнял задачи, которые раньше делали специально обученные люди, но оставался не более чем механизмом. Итак, слабый искусственный интеллект — это в принципе не интеллект, и язык науки и культурный контекст лишь вводят в заблуждение.
Учитывая изложенное выше, стоит поискать другой термин. Слова «искусственный интеллект» прижились в отечественных работах по гуманитарным и социальным наукам и вошли в официальные документы. В то же время технические специалисты часто используют термин «машинное обучение» (machine learning). Вопрос о соотношении этих понятий является спорным. Обычно говорят, что машинное обучение — это технология слабого искусственного интеллекта, причём наиболее популярная. Любопытен график поисковых запросов по фразам «artificial intelligence» и «machine learning», который можно посмотреть в Google Trends4.
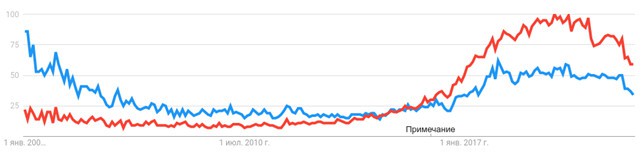
Рисунок 2. График относительной частоты запросов по поисковым фразам «artificial intelligence» и «machine learning» с 2004 г. по настоящее время, полученный с помощью Google Trends.
На графике представлена относительная частота поисковых запросов по фразам «artificial intelligence» (синяя линия) и «machine learning» (красный цвет) с 2004 г. по настоящее время. Слово «примечание» обозначает изменение методики, которое, судя по имеющимся в интернете пояснениям, не повлияло на соотношение частот. Видно, что примерно в 2015 г. тема «machine learning» стала резко наращивать популярность и быстро обогнала тему «artificial intelligence», превысив её частоту в полтора-два раза. По-видимому, из-за распространения технологий машинного обучения этот термин стал чаще использоваться. Несмотря на то что теоретически машинное обучение — это один из потенциальных элементов системы искусственного интеллекта, на практике эти термины применяют как взаимозаменяемые [23, с. 1–2]. Подавляющее большинство современных интеллектуальных систем основаны на машинном обучении.
Термин «машинное обучение» связан с набором особых алгоритмов, способных решать определённый класс задач. Список таких задач и алгоритмов — вопрос дискуссионный. Если алгоритм «учится» на предшествующем «опыте» и тем самым улучшает свою «оценку» в решении задачи, то это машинное обучение [22, с. 686]. Машинное обучение — это процесс, в ходе которого используются наборы данных (проще всего представить их как обыкновенные электронные таблицы), выполняется некоторая программа (алгоритм машинного обучения) и используются ресурсы компьютера (процессор выполняет вычисления, оперативная память хранит данные). Результатом машинного обучения является модель — ещё один алгоритм, который получает какие-то данные и выдаёт какой-то ответ, опираясь на то, чему он «научился».
Конечно, термин «машинное обучение» тоже не идеален, потому что все равно вызывает ассоциации с тем, как учится человек. Тем не менее ни алгоритм, ни набор данных не намекают на какую бы то ни было интеллектуальность — по сути это компьютерная программа. Среди специалистов по машинному обучению есть шутливое утверждение о том, что искусственный интеллект — это перемножение матриц. Матрица — это таблица из чисел, поэтому машинное обучение — это выполнение математических действий над большим набором чисел. Результатом машинного обучения является всего лишь огромная математическая формула, которая превращает одни числа в другие.
Таким образом, нынешний искусственный интеллект — это программы, «обученные» на данных и решающие некоторые задачи, раньше считавшиеся прерогативой человека. Термин «искусственный интеллект» слегка сбивает с толку, а суть явления лучше описывается словами «алгоритм» или «модель машинного обучения». Дальше в тексте работы будет упоминаться искусственный интеллект, потому что это традиционный термин, но не будет подразумеваться какая-либо «интеллектуальность», и по возможности вместо него будет говориться «алгоритм» или «модель». Поскольку искусственный интеллект — это программы, специально настроенные на решение конкретных задач, то и регулирование должно ориентироваться на задачи, которые решаются алгоритмами. В данном исследовании под набором решаемых задач понимается генерация контента: текстов, изображений, аудио и видео.
Охраноспособность: «утиный тест» и тест Тьюринга
Можно ли считать результаты функционирования искусственного интеллекта объектами интеллектуальных прав? При решении этого вопроса исследователи обращаются к понятию творчества [11, с. 535; 8, с. 59]. Творчество традиционно рассматривается как «создание чего-либо нового, ранее не существовавшего» [11], а его основными критериями считают новизну, оригинальность и неповторимость [8]. Можно сказать, что чисто технически алгоритм машинного обучения выдаёт нечто новое. В то же время в научных работах подчёркивается, что для творчества важен субъективный подход: произведение должно быть «тесно связано с личностью автора» [20, с. 41] и отражать его индивидуальность [11, с. 536]. Более того, в более жёстком варианте субъективный подход означает, что автором может быть только человек [12]. Творчество — это способ самовыражения человека, и результат творчества — это нечто, пропущенное сквозь разум и сознание, несущее отпечаток индивидуальности и жизненного опыта и именно в этом качестве охраняемое. Способен ли искусственный интеллект творить и самовыражаться и обладает ли он подобием личности, которая могла бы отразиться в результатах его функционирования?
Учитывая сказанное в начале статьи, личность, самовыражение и творчество в субъективном смысле могут быть только у сильного искусственного интеллекта, которого не существует. Современный искусственный интеллект — это большие математические формулы. Вряд ли у них есть хоть какое-то подобие личности. Следовательно, вопрос об их творчестве — во всяком случае, в субъективном смысле — можно закрыть: нет, алгоритмы машинного обучения не способны творить, и все результаты их функционирования не являются творческими.
Здесь нужно заметить, что творческий характер требуется не для всех охраняемых результатов интеллектуальной деятельности. Например, для охраны базы данных как объекта смежных прав важны не оригинальность и новизна, а существенные инвестиции в создание [16, с. 52]. При этом алгоритмы вполне могут собрать базу данных и затратить на это много ресурсов (например, в виде стоимости доступа к «облачной» инфраструктуре для вычислений). Следовательно, вопрос о том, способен ли алгоритм создать тот или иной вид интеллектуальной собственности, может решаться по-разному. Тем не менее, данная работа посвящена текстам, изображениям, аудио и видео, которые наиболее органично вписываются в круг объектов авторского права, а для авторского права важен творческий труд.
Кажется, будто вопрос об охраноспособности контента, созданного с помощью машинного обучения, можно закрыть: нет творчества — нет объекта авторского права. Однако пока мы абсолютизировали субъективный подход. В его рамках творчеству алгоритмов действительно нет места. Однако, может быть, оно найдётся в объективном подходе? Обратимся к забавному примеру «творчества» с помощью компьютера.
В 2020 г. два человека, юрист-программист и музыкант, сгенерировали все мелодии, которые могут содержаться в одной октаве5. Для этого они написали программу под названием allthemusic6, которая, надо заметить, ничуть не интеллектуальна: она просто перебирает все возможные комбинации нот. Таких комбинаций получилось около 68 миллиардов. Инициаторы проекта сохранили их и загрузили на облачное файловое хранилище (все мелодии в сжатом виде заняли около 1,2 Тб: это много, но не фантастически много, так как компьютеры с накопителями на несколько терабайт продаются в обычных магазинах). Они не смогли однозначно определить, являются ли эти 68 миллиардов композиций объектом авторского права, поэтому решили вопрос так: если не являются, то нет проблем, а если являются, то выдаём открытую лицензию Creative Commons Zero и тем самым разрешаем их использовать всем7. Инициаторы так объяснили цель проекта: бывает, что музыканты написали песни с одинаковой мелодией, и тогда возникают споры, в которых доказать, что совпадение было случайным, почти невозможно8. Автоматически сгенерировать все мелодии — это хороший аргумент в таком споре: он показывает, что мелодии — это не более чем математика9 и что они уже созданы и сделаны свободными для использования.
Вряд ли пример с алгоритмом, создавшим 68 миллиардов мелодий методом полного перебора, перевернёт авторское право. В конце концов, всегда можно сказать, что он доказывает лишь то, что сами по себе короткие мелодии не имеют творческого характера. Тем не менее, в контексте данной работы он важен вот в каком ключе: любое художественное произведение можно представить как случайную комбинацию каких-то исходных элементов. Математически существует множество всех комбинаций букв, звуков, пикселей, и любое произведение литературы, науки или искусства является всего лишь одним из элементов этого множества. Это множество крайне велико: например, набор всех возможных русскоязычных текстов длиной до 1000 символов содержит более 401000 элементов, если учесть пробелы и знаки препинания — но оно не бесконечное. Если существует огромный, но заранее известный и математически определённый набор всех художественных произведений, то что есть творчество: самовыражение личности или извлечение одного элемента из виртуального хранилища? Если это извлечение одного элемента из множества возможных, то почему это может делать только человек? Такое доведение до абсурда показывает, что субъективный подход к творчеству хорош, когда не существует никого другого, кто мог бы создавать некое подобие произведений, но сейчас «другой» появился. Значит, становится уместным объективный подход.
Как же люди могут понять, является ли нечто результатом творчества?
Можно пытаться найти оригинальность, новизну и авторскую индивидуальность, а можно посмотреть на уже признанные произведения, потом — на то, что творчеством не считается, мысленно сравнить и сделать вывод, отнеся спорный объект к классу творческих либо к классу нетворческих. Второй вариант — это оценка по внешнему сходству и вариация «утиного теста»: если птица квакает как утка, ходит как утка, у неё есть перепонки на лапах и перья на теле, и она находится среди других уток, то это, вероятно, утка10. Применительно к произведениям этот тест можно переформулировать так: если что-то выглядит как произведение, воспринимается другими как произведение, и сам автор называет его произведением, то это, вероятно, произведение.
«Утиный тест» для произведений позволяет оторваться от субъективности и снимает жёсткий барьер между человеком и машиной. Сейчас охраноспособность так или иначе связана с самой фигурой «создателя»: результат деятельности человека гораздо охотнее признают объектом авторского права, чем продукт функционирования алгоритма, даже если они по сути одинаковые. Внешняя оценка вслепую, то есть без предварительного указания авторства, ликвидирует это расхождение. С другой стороны, утиный тест больно бьёт по важному правилу авторского права: произведение охраняется независимо от его достоинств. Сравнение конкретного результата выполнения алгоритма с произведениями людей — это поневоле и оценка художественных качеств. Как решить эту проблему?
Чтобы избежать оценки качества конкретного произведения, можно использовать аналог теста Тьюринга. Известно, что в этом тесте человек пытается угадать, с кем он говорит: с компьютером или с другим человеком. Чтобы понять, отличается ли контент, созданный алгоритмом, от произведений, создаваемых человеком, можно перемешать множество примеров и тех, и других творческих работ и показать их нескольким людям. Если люди регулярно путают контент, сгенерированный машиной, и результаты творчества человека, то этот контент можно считать охраноспособным. По-видимому, некоторые алгоритмы пройдут этот тест уже сейчас [15, с. 79]. Такой способ не выглядит лёгким и удобным для практического применения, но его можно использовать в наиболее спорных случаях, а результаты одного теста распространить на аналогичные. Например, если алгоритм прошёл тест на выборке из 30 изображений, то можно считать, что и остальные изображения, сгенерированные данным алгоритмом, являются охраноспособными.
Таким образом, хотя алгоритмы не «творят» в субъективном смысле, они объективно могут создавать нечто, не отличающееся от результатов творчества человека. Если же продукт, сгенерированный алгоритмом, выглядит как произведение, позиционируется как произведение и воспринимается как произведение, то проще всего отнести его к охраняемым результатам интеллектуальной деятельности. Однако отсюда вытекает ряд вопросов. Первый из них — кто автор этого результата? Второй — к какому именно виду результатов интеллектуальной деятельности он относится? Предварительная квалификация в качестве произведения науки, литературы или искусства нуждается в проверке и уточнении. Эти вопросы обсуждаются в следующем параграфе.
Автор: алгоритм вместо человека или человек вместе с алгоритмом?
Вопрос об авторстве тесно связан с правосубъектностью искусственного интеллекта и поэтому выходит за рамки права интеллектуальной собственности и затрагивает теорию, философию и историю права. Суть дискуссии о правосубъектности можно кратко изложить следующим образом. Во-первых, есть принципиальное обоснование как точки зрения о том, что искусственный интеллект — это субъект права, так и прямо противоположной ей11. Во-вторых, есть рассуждения «о наделении правами субъектов, не принадлежащих к человеческому роду» [21, с. 46], например, животных. В-третьих, привязка правосубъектности к биологическим человеческим существам — это проявление узкореалистического подхода к праву [5, с. 23], в то время как в нормативистском подходе [5, с. 23] и в рамках «права и экономики» [5, с. 26] лицо — это не человек, а абстракция, и даже само латинское понятие persona, согласно одному из переводов, означает не личность как таковую, а маску, надеваемую поверх лица [5, с. 18]. Следовательно, понятие лица можно распространить не только на людей и их общности. Хотя вопрос о правосубъектности роботов пока не очень актуален [1, с. 51], в будущем сначала роботы с искусственным интеллектом, а потом и сам искусственный интеллект могут стать субъектами права [7, с. 99]. При этом нужно учитывать интересы и цели: так, правосубъектность искусственного интеллекта может быть нужна его разработчикам, чтобы ограничить свою ответственность [15, с. 84]. Таким образом, в науке нет запрета на правосубъектность искусственного интеллекта, есть предпосылки для её возникновения и идёт обсуждение разных вариантов наделения «роботов» статусом субъекта права. Но есть ли в этом смысл применительно к авторству?
«Сильный» искусственный интеллект мог бы стать субъектом права, но его не существует. «Слабый» — это не интеллект, а алгоритм, решающий конкретную задачу. Да, раньше считалось, что только человек может выполнить эту задачу, а сейчас программа делает то же не хуже человека, но из этого не следует, что появилось нечто человеческое: большая математическая формула остаётся формулой, и сходство результатов её функционирования с результатами работы человека говорит лишь о том, что люди научились автоматизировать задачи, которые раньше не умели автоматизировать. Это свидетельствует о прогрессе в компьютерных науках, но не о появлении нового субъекта права.
Попытка признать алгоритмы субъектами права противоречит редукционизму: «электронное лицо» — это новая сущность, необходимость которой сомнительна. Права животных [21, с. 46], рек [24] и человекообразных роботов12 — это всё же экзотика. Обычно понятие «субъект права» строится вокруг одного или нескольких реальных людей. Возможно, человек не будет субъектом права (если он раб), а может быть, у одного человека будет несколько субъектов (если предприниматель создал несколько хозяйственных обществ), но человек где-то есть, и вопрос о том, появится ли у этого человека юридическая «маска», и сколько их будет, решается исходя из задач регулирования. В случае с алгоритмами «человек на заднем плане» — это разработчик. Есть ли смысл в том, чтобы отделить часть прав и обязанностей такого человека и передать их некоторой новой сущности? Вряд ли: личные неимущественные права автору-алгоритму ни к чему, так как он не почувствует их, а имущественные права он не сможет осуществлять самостоятельно. Задача гражданского права — это регулирование имущественных и некоторых неимущественных отношений, и её можно реализовать, не делая алгоритм субъектом права. Если авторство алгоритма и имеет для кого-то значение, то только для разработчика как средство самовыражения и для третьих лиц как информационное сообщение. В таком случае название алгоритма является чем-то наподобие псевдонима разработчика, но алгоритм сам по себе не становится автором.
Авторство алгоритмов порождает и практические проблемы. Физические и юридические лица регистрируются. По-видимому, регистрация потребуется и для «электронных лиц». Однако обучить модель, способную творить, несложно. Каждый человек с компьютером — это потенциальная фабрика электронных лиц. В такой ситуации появится много неучтённых электронных лиц, или же государство будет завалено потоком запросов на регистрацию. Если признавать субъектами только некоторые наиболее важные алгоритмы, то понадобятся критерии и возникнут сложности с их применением на местах. Кроме того, нужно будет что-то делать с «родством» моделей машинного обучения: есть типовые алгоритмы, и их можно незначительно модифицировать, получая каждый раз новый результат.
Таким образом, правосубъектность алгоритмов не основана на реальном положении вещей, а авторство моделей машинного обучения создаёт много проблем и, видимо, не решает ни одной. Тем не менее с объективной точки зрения некоторые результаты функционирования алгоритмов не отличаются от произведений, созданных человеком. Следовательно, такие произведения должны получить некоторую правовую охрану. У произведения должен быть автор. Автором не может быть алгоритм. Итак, если алгоритм произвёл нечто похожее на результат интеллектуальной деятельности, то кто будет автором и каким именно видом объектов интеллектуальных прав будет считаться это нечто, сгенерированное алгоритмом?
Алгоритмы и модели машинного обучения — это по сути компьютерные программы: код на языке программирования и связанные с ним данные, которые обрабатывают поступающую на вход информацию и отправляют на выход другую информацию. При этом программа для ЭВМ — это отдельный вид объектов интеллектуальных прав. В статье 1261 ГК РФ говорится, что программа для ЭВМ — это не только данные и код, но и аудиовизуальные отображения, порождаемые программой. Если толковать статью буквально, то любой контент, созданный моделью машинного обучения — это аудиовизуальное отображение программы для ЭВМ: так или иначе, сгенерированный текст, изображение, звук или видео будет выведен на внешнее устройство и станет «отображением» результата функционирования программы. Широта понятия «отображение» позволяет распространить его на любой контент. Вряд ли такое толкование соответствует замыслу законодателя: норма, по-видимому, была рассчитана на запрограммированные элементы интерфейса или на графику компьютерной игры, так как во время принятия четвёртой части Гражданского кодекса РФ не было «креативных» моделей машинного обучения. Однако расширительное толкование существующей нормы удобно: оно позволяет привязать любой контент, произведённый моделью машинного обучения, к автору и правообладателю компьютерной программы. Возможность использования такого контента третьими лицами определяется лицензионным договором с правообладателем алгоритма. Такой подход отчасти напоминает computer-generated works, существующие в английском праве [8, с. 62].
Впрочем, вариант, неразрывно связывающий контент с алгоритмом, не слишком удобен для оборота. Можно взглянуть на проблему под другим углом. Сравним контент, сгенерированный моделью машинного обучения, с фотографией: и то, и другое — нечто, полученное с помощью технического устройства. Правовой режим фотографий был и остаётся под вопросом: информационные фотографии, по-видимому, должны рассматриваться как факт, не являющийся интеллектуальной собственностью, а эстетические могут признаваться объектом авторского права. Если человек вносит творческий вклад в снимок и выражает свою индивидуальность, выбирая композицию, освещение, настройки фотоаппарата, технику обработки готовой фотографии, то она получает авторско-правовую охрану [14, с. 56–58]. Напротив, снимки, полученные без участия человека, не считаются объектом интеллектуальных прав [14, с. 65–66]. Такую же идею можно применить в отношении контента, созданного с помощью машинного обучения: он получает правовую охрану в рамках авторского права, если человек вносит в него творческий вклад.
Вернёмся к изображению, приведённому в начале статьи. Автор получил его не сразу. Сначала он придумал текстовую фразу «правовые аспекты искусственного интеллекта», отправил её в нейросеть, увидел результат, который ему не понравился. Далее автор перевёл эту фразу на английский язык и попробовал получить ещё одно изображение, но результат по-прежнему разочаровывал. Тогда автор взял запрос «робот-художник». В ответ на него нейросеть предложила шесть вариантов, из которых автор выбрал один, лучше всего соответствующий его замыслу: человек, сидящий перед компьютером и частично сливающийся с ним, наиболее точно передаёт один из основных выводов данного исследования.
Приведённый выше личный пример типичен для работы с алгоритмами машинного обучения: как минимум нужно предоставить им данные для работы, а получив результат, оценить его, выбрать и отредактировать наилучший вариант. Например, чтобы алгоритм написал статью, нужно выбрать тему статьи, указать ключевые слова, подключить источники информации, изучить варианты, выбрать наиболее приемлемый, отредактировать и вычитать его. Подготовительная и последующая работа с алгоритмом похожа на творческий вклад фотографа. Иначе говоря, машинное обучение является ещё одним инструментов в руках автора — да, более продвинутым, чем ранее существовавшие, но все равно инструментом. Следовательно, вопрос не в том, что машина стала творить сама — вопрос в том, что процесс творчества изменился:
1) автор не пишет текст с нуля, а просит машину подготовить черновики на заданную тему, после чего выбирает наиболее удачный и редактирует его;
2) художник не рисует картинку сам, а просит машину сгенерировать изображение по конкретному запросу и с конкретными параметрами, после чего оценивает результат и редактирует его;
3) композитор не пишет музыку с нуля, а просит машину создать несколько вариантов с заданными настройками, после чего слушает варианты мелодий, выбирает наиболее подходящий и дописывает остальную композицию;
4) автор видео генерирует текст, изображения и звук с помощью алгоритмов и сводит их вместе.
Таким образом, алгоритм сам по себе создаёт не произведения, а только аудиовизуальные отображения, но вклад человека может превратить их в объекты авторского права. Чистого творчества в такой работе меньше, и роль автора приближается к роли редактора, но его минимальный творческий вклад сохраняется и выражается в постановке задачи для модели машинного обучения и в оценке, отборе и редактировании результата её функционирования. Кроме того, автор, создающий произведение с помощью машинного обучения, может адаптировать алгоритмы под свои нужды точно так же, как художники — делать собственные краски или кисти, а музыканты — свои инструменты. Человек, который придумал идею произведения, выбрал алгоритм для её создания, дал ему задачу и довёл результат её выполнения до надлежащего вида, является автором и правообладателем. При этом вопрос о правах на алгоритмы и модели машинного обучения решается так же, как вопрос с правами на любую другую программу, используемую для творчества. Если алгоритмы станут более самостоятельными, то такое решение проблемы авторства нужно будет корректировать, но на данный момент креативный искусственный интеллект — это всего лишь умная кисть в руках человека.
Выводы
Современный искусственный интеллект — это алгоритмы и модели машинного обучения. Они не обладают интеллектом, разумом и сознанием и по сути представляют собой компьютерные программы, созданные для эффективного решения определённого круга задач. Иными словами, это способ автоматизации задач, о которых ранее считалось, что их может выполнить исключительно человек.
Алгоритмы и модели машинного обучения не творят в буквальном смысле слова, так как в их функционировании отсутствует необходимый для творчества субъективный элемент. В то же время объективно результаты их функционирования могут быть неотличимы от произведений, созданных человеком, и возникает вопрос о необходимости правовой охраны таких результатов. Чтобы понять, есть ли у результата работы алгоритма некое подобие оригинальности и новизны, можно использовать «утиный тест» (то, что выглядит как произведение, воспринимается как произведение и позиционируется как произведение, является произведением) и адаптированный тест Тьюринга (если люди массово путают человеческие произведения и контент, сгенерированный машиной, то контенту можно дать правовую охрану).
Алгоритмы и модели машинного обучения — не субъекты права, и нет смысла делать их субъектами права. Контент, созданный ими, сам по себе является аудиовизуальным отображением программы для ЭВМ. Однако человек ставит программе задачу, оценивает и редактирует результат, модифицирует и настраивает программу под свои нужды, что можно считать минимальным творческим вкладом. При наличии достаточного творческого вклада человек можно сказать, что создаёт произведение науки, литературы или искусства, используя в качестве инструмента алгоритм или модель машинного обучения. Произведение, созданное с помощью машинного обучения, является объектом авторского права, а его автором и правообладателем является человек, организовавший создание произведения. При этом вопрос о правах правообладателя алгоритма или модели машинного обучения решается на основании лицензионного договора так же, как и в случае с другими программами, используемыми для творчества.
1 Оригинальная страница с изображением находится по адресу: https://rudalle.ru/check_image/bda9ccb9fe2d4f0bae795ad712e035a1 (дата обращения: 03 мая 2022 г.).
2 Других намёков на авторство изображения на странице нет.
3 Заслуживает внимание ремарка о природе юридического мира как ars («нечто искусственное, научно созданное… пребывающее в вымышленном… мире идей»), которую сделал Г.А. Гаджиев в статье о роботе как субъекте права [5, с. 18].
4 https://trends.google.com/trends/explore?date=all&q=artificial%20intelligence,machine%20learning (дата обращения: 03 мая 2022 г.).
5 Программист и музыкант алгоритмически сгенерировали все возможные мелодии и сделали их общественным достоянием // Хабр. URL: https://habr.com/ru/news/t/489982/ (дата обращения: 03 мая 2022 г.).
6 URL: (дата обращения: 03 мая 2022 г.).
7 URL: http://allthemusic.info/faqs/#If_ATM_is_copyrightable_then_Creative_Commons_Zero_CC0_If_ATM<...> (дата обращения: 03 мая 2022 г.).
8 URL: http://allthemusic.info/faqs/#Whats_your_project (дата обращения: 03 мая 2022 г.).
9 URL: http://allthemusic.info/faqs/#Melodies_are_math_Finite_combinations_of_notespitches (дата обращения: 03 мая 2022 г.).
10 Есть разные формулировки этого «теста». Приведённая в тексте взята из подписи к иллюстрации в одной медицинской научной статье, найденной в интернете по запросу «duck principle». URL: https://www.researchgate.net/figure/The-Duck-Principle-But-when-I-see-a-bird-that-quacks-like-a-duck-walks-like-a-duck_fig1_353749261 (дата обращения: 03 мая 2022 г.). Другие формулировки похожи на неё, но отличаются деталями.
11 Обычно при этом ссылаются на статью Л. Соулума о правосубъектности электронного интеллекта. В частности, И.В. Понкин и А.И. Редькина указывают, что Л. Соулум сконструировал как аргументы, доказывающие необоснованность признания искусственного интеллекта субъектом права, так и контраргументы [13, с. 96].
12 Речь об истории, когда Саудовская Аравия дала гражданство роботу Софии. Нужно заметить, что С.А. Соменков ставит информацию о правосубъектности робота под сомнение [15, с. 84]. В то же время твит о присвоении гражданства роботу, опубликованный в аккаунте Центра международных коммуникаций Саудовской Аравии, по-прежнему доступен: https://twitter.com/CICSaudi/status/923212096552218624 (дата обращения: 03 мая 2022 г.).
Список литературы
1. Архипов В.В., Наумов В.Б. Искусственный интеллект и автономные устройства в контексте права: о разработке первого в России закона о робототехнике // Труды СПИИРАН. — 2017. — Вып. 6 (55). — С. 46–62. — DOI: 10.15622/sp.55.2.
2. Бегишев И.Р., Хисамова З.И. Криминологические риски применения искусственного интеллекта // Всероссийский криминологический журнал. — 2018. — Т. 12, № 6. — С. 767–775.
3. Васильев А.А., Шпоппер Д., Матаева М.Х. Термин «искусственный интеллект» в российском праве: доктринальный анализ // Юрислингвистика. — 2018. — №7–8. — С. 35–44. — DOI 10.14258leglin(2018)7-804.
4. Войниканис Е.А., Семёнова Е.В., Тюляев Г.С. Искусственный интеллект и право: вызовы и возможности самообучающихся алгоритмов // Вестник Воронежского государственного университета. Серия: Право. — 2018. — № 4 (35). — С. 137–148.
5. Гаджиев Г.А. Является ли робот-агент лицом? (Поиск правовых форм для регулирования цифровой экономики) // Журнал российского права. — 2018. — № 1. — С. 15–30.
6. Косьяненко Е.М. Применение норм интеллектуального права при использовании технологий искусственного интеллекта // Бизнес, менеджмент и право. — 2019. — № 3. — С. 25–29.
7. Лаптев В.А. Понятие искусственного интеллекта и юридическая ответственность за его работу // Право. Журнал Высшей школы экономики. — 2019. — № 2. — С. 79–102. — DOI 10.17-323/2072-8166.2019.2.79.102.
8. Малахова Н.Л., Присяжнюк Ю.П., Сперанская Ю.С. Результаты интеллектуальной деятельности, созданные искусственным интеллектом // Российский правовой журнал. — 2020. — № 2 (3). — С. 57–65.
9. Морхат П.М. Искусственный интеллект: правовой взгляд: Научная монография / РОО «Институт государственно-конфессиональных отношений и права». — М.: Буки Веди, 2017. — 257 с.
10. Наумов В.Б. Право в эпоху цифровой трансформации: в поисках решений // Российское право: образование, наука, практика. — 2018. — № 6. — С. 4–11.
11. Наумов В.Б., Тытюк Е.В. К вопросу о правовом статусе «творчества» искусственного интеллекта // Правоведение. — 2018. — Т. 62, № 3. — С. 531–540. — DOI 10.17-323/2072-8166.2019.2.79.102.
12. Петраков Н.А. Проблемы правовой охраны объектов, созданных посредством цифровых технологий // Журнал Суда по интеллектуальным правам. — 2021. — URL: http://ipcmagazine.ru/yaa/problems-of-legal-protection-of-objects-created-using-digital-technologies (дата обращения: 28.01.2022).
13. Понкин И.В., Редькина А.И. Искусственный интеллект с точки зрения права // Вестник РУДН. Серия: Юридические науки. — 2018. — Т. 22, № 1. — С. 91–109. — DOI 10.22363/2313-2337-2018-22-1-91-109.
14. Рожкова М.А., Исаева О.В. Правовые режимы фотографии в российском праве // Журнал Суда по интеллектуальным правам. — 2021. — № 2 (32). — С. 55–69.
15. Соменков С.А. Искусственный интеллект: от объекта к субъекту // Вестник Университета им. О. Е. Кутафина (МГЮА). — 2019. — № 2. — С. 75–85. — DOI 10.22363/2313-2337-2018-22-1-91-109.
16. Сосипатрова Н.Е. База данных как объект интеллектуальных прав: виды, критерии правовой охраны, режим использования // Законность и правопорядок. — 2019. — № 4 (24). — С. 51–55.
17. Филипова И.А. Трансформация правового регулирования труда в цифровом обществе. Искусственный интеллект и трудовое право / И.А. Филипова. — Нижний Новгород: Нижегородский госуниверситет им. Н.И. Лобачевского, 2019. — 89 с.
18. Харитонова Ю.С., Савина В.С. Технология искусственного интеллекта и право: вызовы современности // Вестник Пермского университета. Юридические науки. — 2020. — Вып. 49. — С. 524–549. — DOI: 10.17072/1995-4190-2020-49-524-549.
19. Хисамова З.И., Бегишев И.Р. История становления и теоретико-правовые подходы к толкованию понятия «искусственный интеллект» // Алтайский юридический вестник. — 2020. — № 3(31). — С. 31–38.
20. Шахназарова Э.А. Правовое регулирование отношений, возникающих по поводу объектов интеллектуальной собственности, созданных технологией искусственного интеллекта, на примере опыта Великобритании, США и ЕС // Журнал Суда по интеллектуальным правам. — 2021. — № 2 (32). — С. 34–45.
21. Ястребов О.А. Правосубъектность электронного лица: теоретико-методологические подходы // Труды Института государства и права РАН. — 2018. — Т. 13, № 2. — С. 36–55.
22. Janiesch C., Zschech P., Heinrich K. Machine learning and deep learning // Electronic Markets. — 2021. — Vol. 31. — P. 685–695. — DOI: 10.1007/s12525-021-00475-2.
23. Kuhl N., Goutier M., Hirt R., Satzger G. Machine Learning in Artificial Intelligence: Towards a Common Understanding. — 2019. — URL: https://arxiv.org/abs/2004.04686 (date of retrieval: 27.01.2022).
24. O'Donnell E.L., Talbot-Jones J. Creating legal rights for rivers: lessons from Australia, New Zealand, and India // Ecology and Society. — 2018. — Vol. 23 (1). — Art. 7. — DOI: 10.5751/ES-09854-230107.